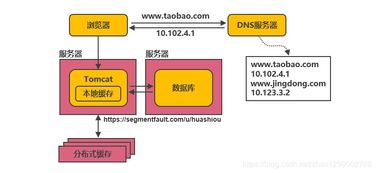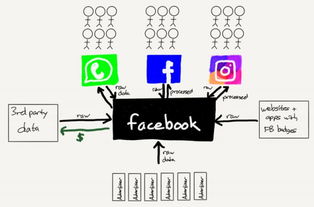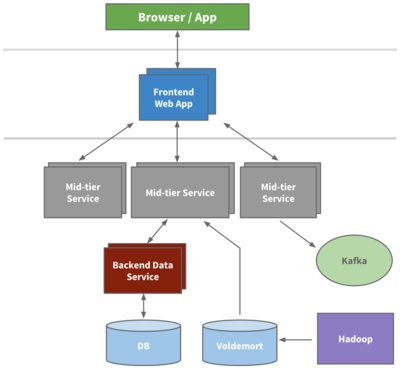
在過去的十年中,LinkedIn 的架構經歷了從單體到微服務、從集中式到分布式的重大演進,尤其是在數據處理服務方面,其發展軌跡堪稱行業典范。數據處理作為 LinkedIn 業務的核心支撐,不僅驅動了用戶推薦、內容分發和實時分析等功能,還應對了爆炸式增長的數據規模和復雜性。本文將回顧 LinkedIn 在過去十年中數據處理服務的演變,從早期的基礎設施到如今的智能平臺,探討其背后的技術決策、關鍵里程碑以及未來趨勢。
早期階段(約 2010-2015 年):單體架構與批處理為主
在 LinkedIn 的早期,架構以單體設計為主,數據處理主要依賴批處理系統,如 Hadoop 生態系統。這一時期,數據量雖快速增長但相對可控,LinkedIn 開始構建數據湖,使用 Apache Kafka 作為消息隊列來支持數據流的傳輸。數據處理服務側重于離線分析,例如用戶行為日志處理和批量推薦算法,但實時性需求不高。挑戰包括數據一致性和擴展性問題,LinkedIn 通過引入分區和復制策略來優化。
中期演進(約 2015-2020 年):微服務化與實時處理興起
隨著 LinkedIn 用戶量突破 5 億,數據處理需求轉向實時化和高可用性。公司大力推動微服務架構轉型,數據服務被拆分為獨立的組件,如 LinkedIn 的 Espresso 分布式數據庫和 Samza 流處理框架。這一階段,數據處理服務開始強調低延遲,支持實時推薦、通知系統和欺詐檢測。例如,Samza 與 Kafka 集成,實現了事件驅動的數據處理管道,顯著提升了用戶體驗。同時,數據治理和隱私保護成為焦點,LinkedIn 建立了更嚴格的數據訪問控制機制。
近期發展(約 2020 年至今):云原生與 AI 驅動的智能平臺
進入 2020 年代,LinkedIn 全面擁抱云原生技術,數據處理服務轉向容器化和無服務器架構。利用 Kubernetes 和云基礎設施,服務實現了更高的彈性和成本效率。AI 和機器學習深度集成,數據處理不再局限于存儲和分析,而是驅動個性化內容、職業洞察和自動化決策。例如,LinkedIn 使用機器學習模型進行實時內容排序,并通過數據湖和 Delta Lake 技術確保數據質量。數據流水線更加自動化,支持多租戶和跨地域部署,以應對全球化業務的復雜性。
關鍵挑戰與經驗教訓
十年來,LinkedIn 在數據處理服務上面臨的主要挑戰包括數據規模爆炸、實時性需求和安全性問題。通過采用開源工具(如 Kafka、Samza 和 Pinot)和內部創新,LinkedIn 實現了從批處理到流處理的平滑過渡。經驗表明,模塊化設計、持續監控和敏捷迭代是成功的關鍵。例如,在 2016 年的一次大規模數據遷移中,LinkedIn 通過分階段部署避免了服務中斷。
未來展望
LinkedIn 的數據處理服務預計將進一步智能化,結合邊緣計算和聯邦學習,以提升隱私保護和響應速度。同時,隨著 AI 倫理和法規的演進,數據服務將更注重透明度和合規性。LinkedIn 的架構演進不僅展示了技術的前沿趨勢,也為其他企業提供了寶貴參考。
LinkedIn 的十年數據處理服務之旅是一個從傳統批處理到實時智能化的轉型故事。通過持續的架構創新,LinkedIn 不僅支撐了其社交網絡的增長,還推動了整個行業的數據處理標準。無論是早期的基礎設施建設,還是如今的 AI 賦能,LinkedIn 始終以用戶為中心,驅動數據價值最大化。