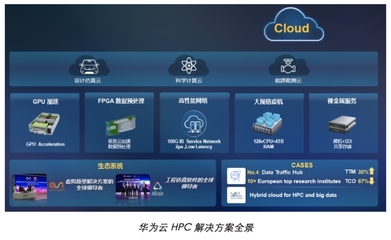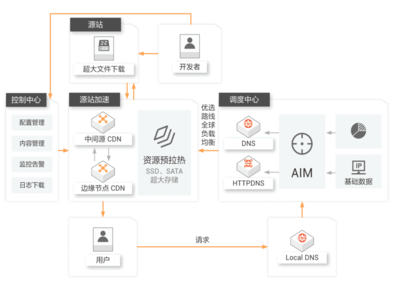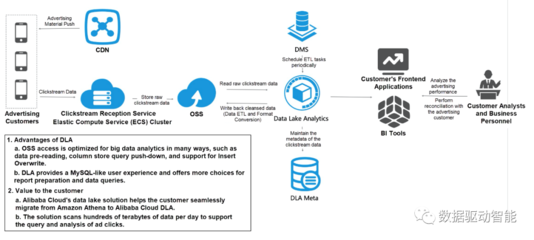
在數據湖的上篇中,我們討論了數據存儲和集成的基礎。本篇將聚焦于數據處理服務,這是數據湖實施的關鍵環節。通過高效的數據處理服務,企業能夠將原始數據轉化為可操作的洞見,從而支持決策和創新。
一、數據處理服務的重要性
數據處理服務是數據湖架構的核心,負責數據清洗、轉換、分析和建模。它確保數據在進入數據湖后能夠被快速、準確地利用,避免數據沼澤(數據堆積但無法有效使用)的發生。隨著企業數據量的爆炸式增長,自動化、實時處理的需求日益突出,這進一步凸顯了數據處理服務在提升數據價值方面的作用。
二、核心組件與技術選型
數據處理服務通常包括以下組件:
- 數據清洗與轉換:使用工具如Apache Spark或AWS Glue,去除重復、錯誤數據,并標準化格式。例如,通過ETL(提取、轉換、加載)流程,將原始日志轉換為結構化的業務數據。
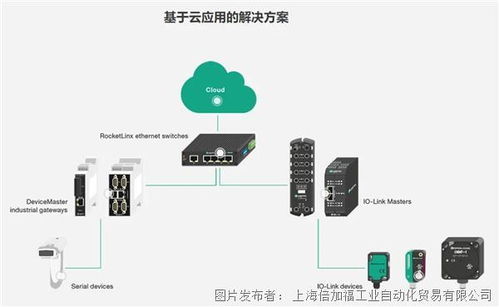
- 數據流處理:對于實時數據,采用Apache Kafka或Flink實現流式處理,支持即時分析和響應。例如,在電商場景中,實時處理用戶點擊流數據以優化推薦系統。
- 數據建模與ML集成:利用機器學習框架(如TensorFlow或PyTorch)構建預測模型,并通過服務化(如REST API)將結果集成到業務應用中。這有助于企業實現智能化運營。
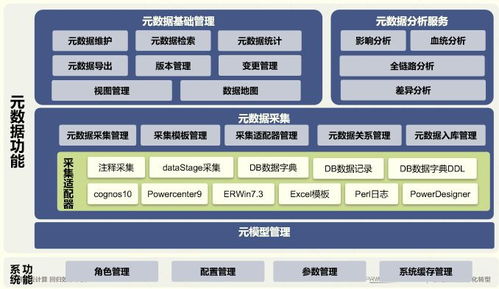
- 元數據管理:通過工具如Apache Atlas或AWS Lake Formation管理數據血緣和權限,確保數據處理過程的可追溯性和合規性。
在選擇技術時,企業應考慮成本、可擴展性和團隊技能。例如,云原生服務(如Azure Data Factory)可降低運維負擔,而開源工具則提供更高的靈活性。
三、實施步驟與最佳實踐
為了成功實施數據處理服務,企業可遵循以下步驟:
- 需求分析:明確業務目標,如實時監控、預測分析或報告生成,并據此設計處理流程。
- 架構設計:構建分層處理架構,包括原始數據層、處理層和服務層。例如,使用Lambda架構同時支持批處理和流處理。
- 自動化與監控:實施自動化管道,并通過工具如Prometheus監控性能指標,及時優化資源使用。
- 安全與治理:集成數據加密、訪問控制和審計機制,確保數據處理符合法規(如GDPR)。
- 迭代優化:從小規模試點開始,收集反饋并持續改進,避免一次性大規模部署帶來的風險。
四、挑戰與應對策略
數據處理服務在實施中常見挑戰包括:
- 數據質量問題:通過建立數據質量框架和使用自動驗證工具來緩解。
- 性能瓶頸:采用分布式計算和緩存技術(如Redis)提升處理速度。
- 成本控制:利用云服務的彈性計費模式,優化資源分配。
五、案例與展望
以某金融企業為例,通過實施基于Spark的數據處理服務,實現了交易數據的實時風險分析,處理時間從小時級降至秒級。未來,隨著AI和邊緣計算的發展,數據處理服務將更加智能化,幫助企業在競爭中保持領先。
數據處理服務是數據湖成功的關鍵。企業應結合自身需求,選擇合適的技術和流程,將數據轉化為真正的資產。如果您需要更多細節,歡迎繼續探討。